Can you imagine asking in natural language questions about your data? In this blog, I will demonstrate how you can leverage the power of Language Models (LLMs), with a focus on ChatGPT, to request information about the data stored in your ERP system.
This article provides a general overview but to fully grasp what I’ve achieved, it’s helpful to be familiar with the ERP Dynamics 365 Business Central and its functionalities.
Before we proceed, it’s important to emphasize that the procedure I’ll describe is purely experimental and should not be used in a production environment. It’s crucial to keep in mind that transmitting data via APIs can pose security risks and privacy issues.
Prerequisites
To integrate Business Central interact with the GPT model, you will need to invoke the OpenAI APIs. I recommend following OpenAI’s technical documentation, which provides detailed instructions on how to do this. The main steps are as follows:
- Register on OpenAPI.
- Request the API Key for authentication.
- Follow the instructions on the site that describe how to invoke the API.
Alternatively, you can also use the Azure OpenAI service. The experiments for this blog were conducted using the ChatGPT 3.5 turbo model.
The Prompt
The main input to provide to the API is the prompt, which allows giving specific instructions and requests to our assistant (ChatGPT). Each prompt can consist of multiple parts, each associated with a role. This helps define the behavior and response of the model. Specifically, the roles we will use are:
- System: to set the assistant’s behavior and provide specific instructions on how it should act during the conversation.
- User: for requests or comments that the model should respond to. In this part, we will also provide the ERP data that the model needs to answer questions.
In our case, we will be using customer data. Here is a schema to describe how the final prompt is composed.
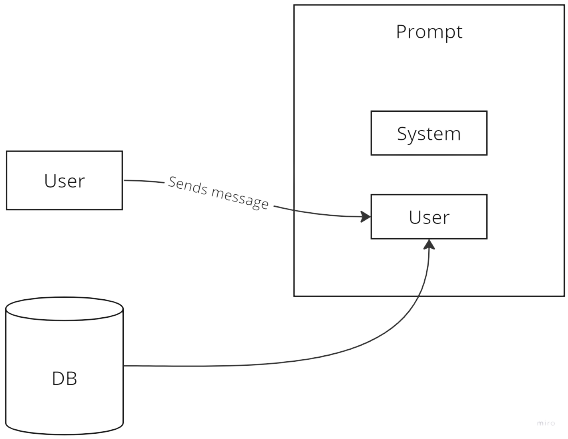
For the system role of the prompt, I have set the following message:
Answer the question based on the dataset in CSV format with semicolon as separator shown below. For any information requested that is not present in the provided dataset please answer “I could not find an answer”.
The user role of the prompt is as follows:
I’m from the sales department, and I need your help with some calculations based on our customer data. Here’s the customer data we have in a CSV format:
{customer data here}
My question about data is: {user question}.
We will now proceed to see the results obtained. Before we continue, I would like to inform you that all the code developed in AL is available on my GitHub. I only ask for a small favor, which is to follow me on my LinkedIn and GitHub. Thank you.
Testing phase
At the time of testing, the customer data present in the trial company of Business Central (Cronus IT) were as follows:
| No. | Name | Sales (LCY) | Country/Region Code |
| 1 | Adatum Corporation | 215603,80 | IT |
| 2 | Trey Research | 49122,10 | IT |
| 3 | School of Fine Art | 220892,70 | US |
| 4 | Alpine Ski House | 66633,30 | DE |
| 5 | Relecloud | 84376,90 | IT |
These data are read real-time from the database and inserted into the prompt in CSV format substituting the placeholder of the user role {customer data here}. Finally, I have added an action to the customer list to invoke the chat. The Request field will replace the user role placeholder {user question}:
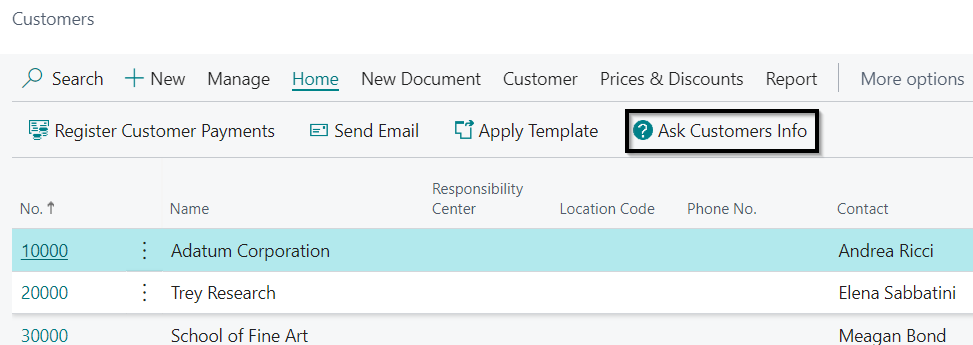

Let’s start with questions that will also require mathematical calculations:
- What is the total sales amount for all customers in the dataset?

- How many customers are from each country/region in the dataset?
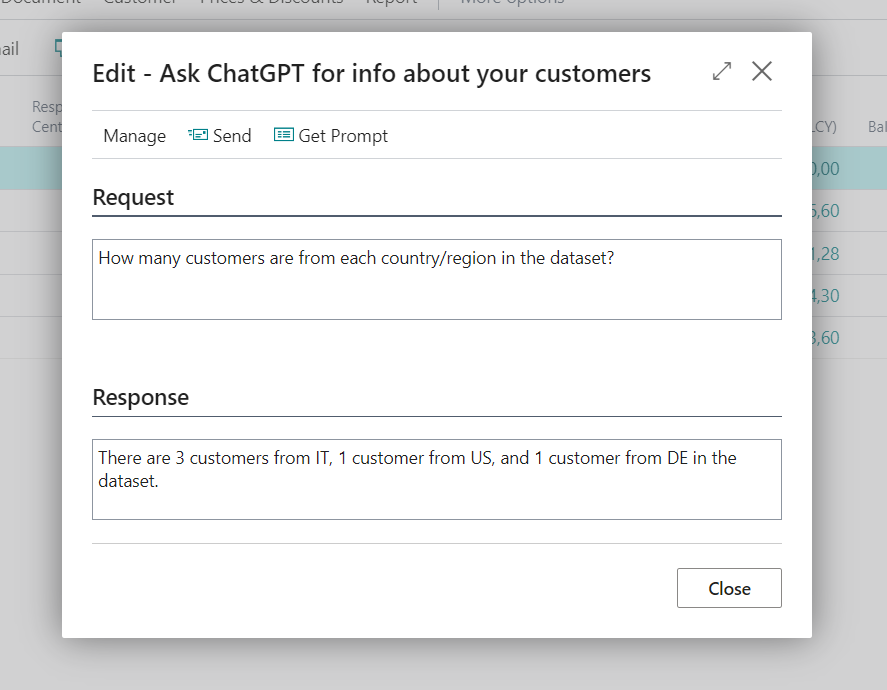
- What is the sum of the sales amount of Italian customers?
- What is the sales amount grouped by country?
- What is the capital of Italy?

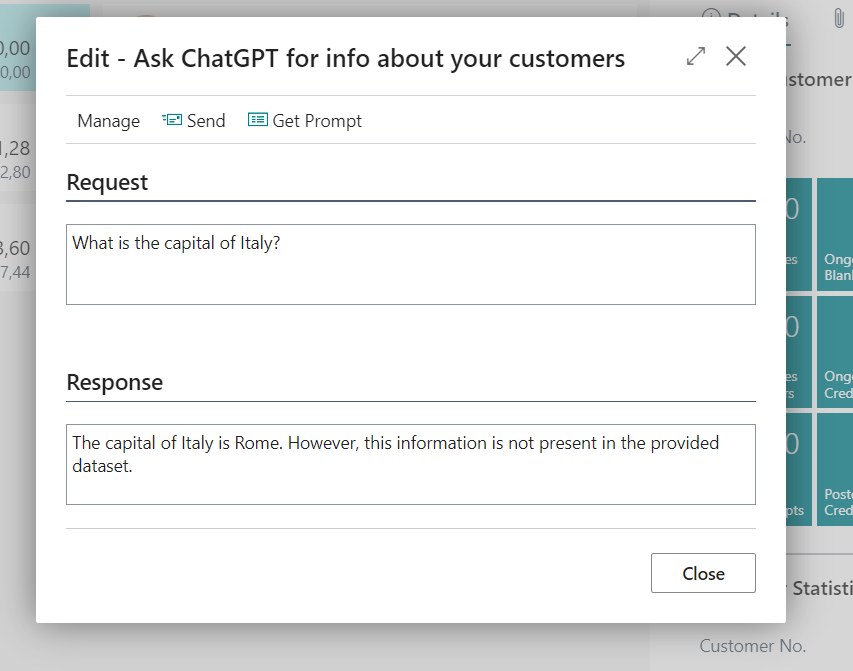
In this last question, the model responds correctly by specifying that the information is not present in the dataset available to it. However, considering the prompt, I would expect the response to be “I could not find an answer.” I still did not find a way to limit it completely to the data set provided.
Conclusion
In this blog, we have explored how it is possible to integrate structured data from our ERP system with ChatGPT, showcasing the model’s ability to provide appropriate and relevant responses. However, there are several limitations to this solution, with scalability being the primary concern. It is evident that this method cannot work with larger datasets due to the well-defined token limit of the prompt. In such situations, it is necessary to explore more refined solutions, such as the following:
- Fine-tuning: This technique allows for further training the model for a specific task or domain. It enables the model to acquire a better understanding and response capability within the specific context.
- Embedding: This technique involves representing words, phrases, and more as multidimensional vectors. By using a vector database, the vector that best matches the user’s query can be extracted using vector distance as a criterion. This vector will form the context for the prompt that GPT will analyze.
In conclusion, these advanced solutions overcome the scalability limitations, providing more accurate and contextually relevant analysis and responses. Stay tuned for upcoming experiments I will conduct on this topic.